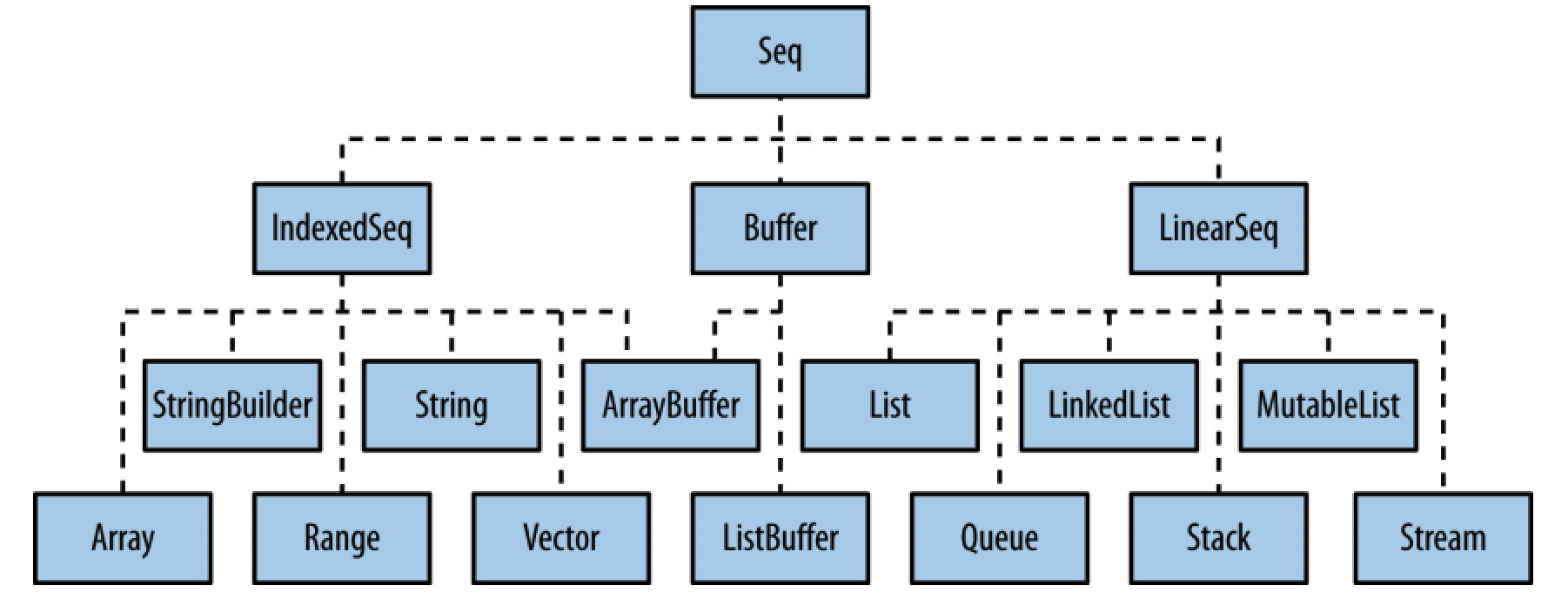
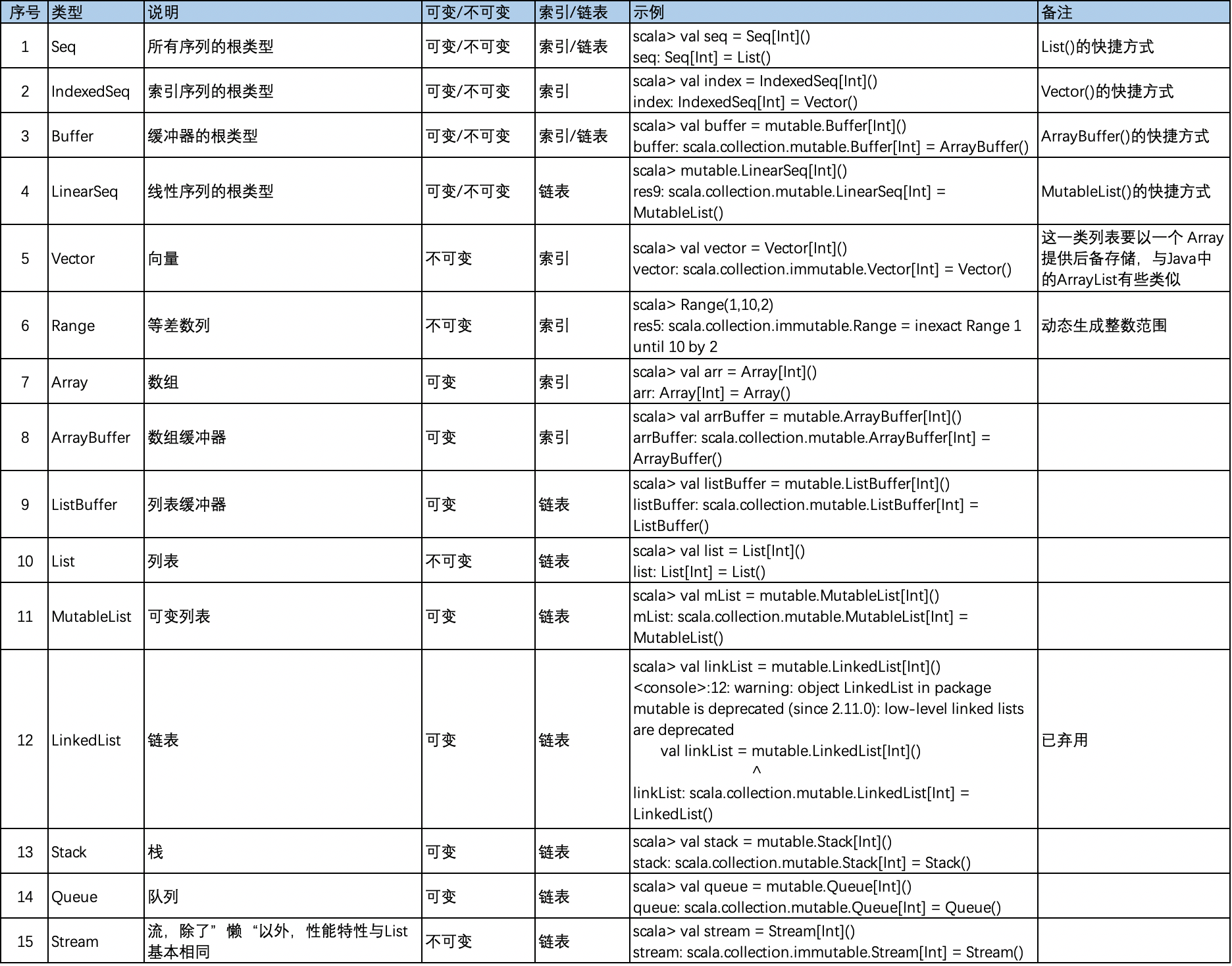
Seq 是所有序列(有序集合)的根类型,序列集合的 Seq 层次体系如图所示:
序列的操作有以下几种:
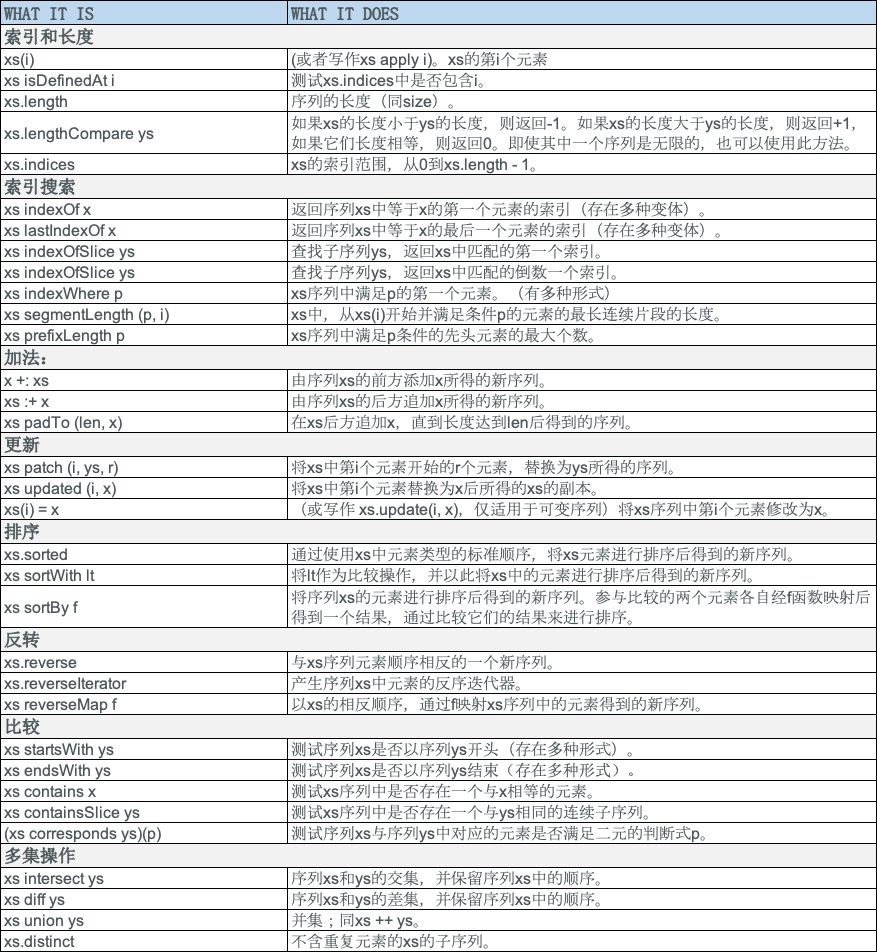
- 索引和长度的操作 apply、isDefinedAt、length、indices,及lengthCompare。序列的apply操作用于索引访问;因此,Seq[T]类型的序列也是一个以单个Int(索引下标)为参数、返回值类型为T的偏函数。换言之,Seq[T]继承自Partial Function[Int, T]。序列各元素的索引下标从0开始计数,最大索引下标为序列长度减一。序列的length方法是collection的size方法的别名。lengthCompare方法可以比较两个序列的长度,即便其中一个序列长度无限也可以处理。
- 索引检索操作(indexOf、lastIndexOf、indexofSlice、lastIndexOfSlice、indexWhere、lastIndexWhere、segmentLength、prefixLength)用于返回等于给定值或满足某个谓词的元素的索引。
- 加法运算(+:,:+,padTo)用于在序列的前面或者后面添加一个元素并作为新序列返回。
- 更新操作(updated,patch)用于替换原序列的某些元素并作为一个新序列返回
- 排序操作(sorted, sortWith, sortBy)根据不同的条件对序列元素进行排序。
- 反转操作(reverse, reverseIterator, reverseMap)用于将序列中的元素以相反的顺序排列。
- 比较(startsWith, endsWith, contains, containsSlice, corresponds)用于对两个序列进行比较,或者在序列中查找某个元素。
- 多集操作(intersect, diff, union, distinct)用于对两个序列中的元素进行类似集合的操作,或者删除重复元素。
Seq 在 Iterator 的基础上添加了其他一些操作 :
Seq trait 具有三个子特征(subtrait):
- 线性序列(LinearSeq):不添加新的操作,具有高效的 head 和 tail 操作,常用线性序列有
scala.collection.immutable.List和scala.collection.immutable.Stream; - 索引序列(IndexedSeq):不添加新的操作,具有高效的apply, length, 和 (如果可变) update操作,常用索引序列有
scala.collection.mutable.ArrayBuffer和scala.collection.immutable.Vector; - 缓冲器(Buffer):缓冲器允许对现有元素进行增、删、改操作,常用的Buffer序列有
ListBuffer和ArrayBuffer,Buffer 在 Seq 的基础上增加了一些添加和删除的操作;
列表(List)
List 是一个不可变链表,它既不能调整大小也不能改变其内容/状态。
List 的创建
创建列表的标准做法
Scala中创建List或者其他类型集合时,标准做法是作为一个函数来调用这个集合,并提供必要的内容:
1 | scala> val colors = List("red", "green", "blue") |
Scala 的列表类型是协变的(covariant),对每一组类型的S和T,如果S是T的子类型,那么List[S]就是List[T]的子类型。空列表的类型是List[Nothing],对任何T来说,List[Nothing] 都是List[T]的子类型,这也是为什么编译器允许我们编写一下代码:
1 | scala> val x = List() |
创建列表的构建单元
所有列表都构建自两个基础的构建单元:Nil 和 ::,Nil 表示空列表,中缀表达式::表示在列表前追加元素,List(…)不过是最终展开成这些定义的包装方法而已
1 | // 以:结束的操作符是右结合的,等价于val colors = ("red" :: ("green" :: ("blue" :: Nil))) |
List 的基本操作
列表原始操作
List 的所有操作都可以用下面三个原始操作来完成:
- head 返回列表的第一个元素,对空列表将抛出异常
- tail 返回列表中除第一个元素之外的所有元素,对空列表将抛出异常
- isEmpty 返回列表是否为空列表
1 | scala> val emptyList = Nil |
与 head 和 tail 方法对应,List还提供了相应的对偶方法,last 获取列表的最后一个元素,init返回除了最后一个元素之外的剩余部分,所不同的是后两种方法的时间复杂度为 O(n)
1 | scala> val abc = List('a', 'b', 'c') |
列表解构
列表支持解构:
1 | scala> val List(a, b, c) = colors |
列表解构可以用于模式匹配:x :: xs 是中缀操作模式的一个特例,中缀操作等同于一次方法调用,而::作为模式有着不同的规则,它是被当做构造方法模式处理的,x::xs相当于 ::(x, xs),Scala中有一个类叫scala.:: 就是用来构建非空列表的。通常,对列表做模式匹配比用方法来解构更清晰,下面是一个使用列表的模式匹配实现插入排序的一个例子
1 | // 插入排序 |
List 的初阶方法
List 继承了 Seq 特质(LinearSeq 没有添加新的操作)中不可变类型的所有方法,此外 List 还增加了一些自身独有的操作。
索引和长度
1 | scala> val abc = List('a', 'b', 'c') |
按索引查找
1 | scala> val list = List(1,2,4,3,2,4) |
列表加法
1 | scala> val y = List(4,5) |
更新
1 | scala> xs |
排序
- xs.sorted:按自然值对核心类型的列表排序(升序),返回一个新列表
1 | // 对数值型来说就是值的大小 |
- sortBy:
xs.sortBy(f)接收一个列表xs,对每个元素调用函数 f,按照函数返回值的自然值对列表中的元素进行排序(升序)
1 | scala> List("w", "da", "h").sortBy(_.size) |
- sortWith:
xs.sortWith(before)接收一个列表 xs,before是一个用来比较两个元素的布尔函数,x before y返回true则代表x应该排列在y前面
1 | scala> List(1, -3 ,4, 2).sortWith(_ < _) |
- 列表反转:由于列表是一个链表,当需要频繁访问列表的末尾时,先将列表反转,操作结束再对反转后的列表进行反转通常是更好的选择
1 | scala> abc.reverse |
比较
1 | // 测试序列xs是否以序列ys开头 |
多集操作
- 集合操作:并非真的”集合“操作,因为不去重
1 | scala> val xs = List(1,1,2,1,3,2,3) |
- 列表扁平化:flatten 方法接收一个列表的列表并将它扁平化,返回单个列表
1 | scala> val efg = List('e', 'f', 'g') |
- 列表拉链/解拉链:zip 方法接收两个列表,一一匹配两个列表中的元素,返回一个元组列表,如果两个列表长度不同则会丢弃没有匹配上的元素;
1 | scala> abc.zip(efg) |
- 列表解拉链:unzip 方法是zip的逆方法,接收一个元组列表,返回一个列表元组
1 | scala> abc.zip(efg).unzip |
var列表赋值
不可变集合同样提供了 += 和 -= 操作,虽然效果相同,但它们在实现上是不同的。可变集合的+=是在可变集合上调用+=方法,它会改变s的内容;但不可变类型的+=却是赋值操作的简写,它是在集合上应用方法+,并把结果赋值给集合变量。这体现了一个重要的原则:我们通常能用一个非不可变集合的变量(var)来替换可变集合的常量(val)。
列表虽然是不可变的,但是可以通过重新赋值来改变列表变量的值,从最终结果来看与使用可变类型相同,但有效率上的差异。
1 | scala> var xs = List[Int]() |
转换列表
列表无处不在,需要集合时推荐优先使用List,Scala的集合类型可以很容易的进行相互转换
- toString 返回列表的标准字符串表现形式;
1 | scala> abc.toString |
- mkString(pre, sep, post) 通过分隔符seq拼接列表中的元素,然后再首位添加前缀pre和后缀;
1 | scala> abc.mkString("[", ",", "]") |
- toArray:将列表转化为数组(顺序表)
1 | scala> abc.toArray |
- copyToArray:将列表中的元素依次复制到目标数组的指定位置
1 | scala> val arr = new Array[Char](10) |
- iterator:将列表转化为迭代器
1 | scala> abc.iterator |
List 的高阶方法
列表映射(map):
- map:
xs.map(f)接收一个列表 xs,依次对列表中每个元素调用 f ,返回一个包含所有返回值的列表
1 | scala> List(1,2,3).map(_ * 2) |
- flatMap:
xs.flatMap(f)接收一个列表 xs,依次对列表中的每个元素调用 f,f 必须要返回一个collection,然后将所有collection拼接起来,返回一个包含所有collection中各个元素的列表
1 | scala> List("ab c", "d e f").flatMap(_.split(" ")) |
- foreach:
xs.foreach(g)接收一个列表 xs, 依次对列表中的每个元素调用过程 g,返回Unit
1 | scala> var sum = 0 |
列表过滤(filter):
- filter:
xs.filter(p)接收一个列表xs,依次对列表中的每个元素调用布尔函数 p,返回包含所有返回值为 true 的元素的列表
1 | scala> List(1,2,3,4).filter(_ % 2 == 0) |
- partition:
xs.partition(p)接收一个列表 xs,依次对列表中的每个元素调用布尔函数 p,返回一个列表二元组,第一个列表包含了所有返回true的元素,第二个列表包含了所有返回false的元素
1 | scala> List(1,2,3,4).partition( _ < 3) |
- find:
xs.find(p)接收一个列表xs,依次对列表中的每个元素调用布尔函数 p,返回一个可选值(Option),如果存在返回值为true的元素x,则返回第一个匹配成功的元素Some(x),否则返回None
1 | scala> List(1,2,3,4).find(_ % 2 == 0) |
列表归约(reduce):
实现归约的三要素:
- 可迭代对象(iterator):进行迭代归约的对象;
- 累加器变量(accumulator):在迭代开始时拥有一个初始值,在迭代过程中基于归约函数和当前元素进行更新,在迭代结束时作为最终的返回值;
- 归约函数(op):接收当前元素和累加器变量更新累加器变量;
Scala 支持数学归约(如计算一个列表的总和)和逻辑归约(例如确定一个列表是否包含给定元素)。Scala支持三种归约的高阶操作:fold、reduce 和 scan,这三个归约操作实际并没有本质区别,可以相互实现。对于每种归约操作,Scala又划分了三个版本:默认版本(等价于从左到右归约)、从左到右归约、从右到左归约。
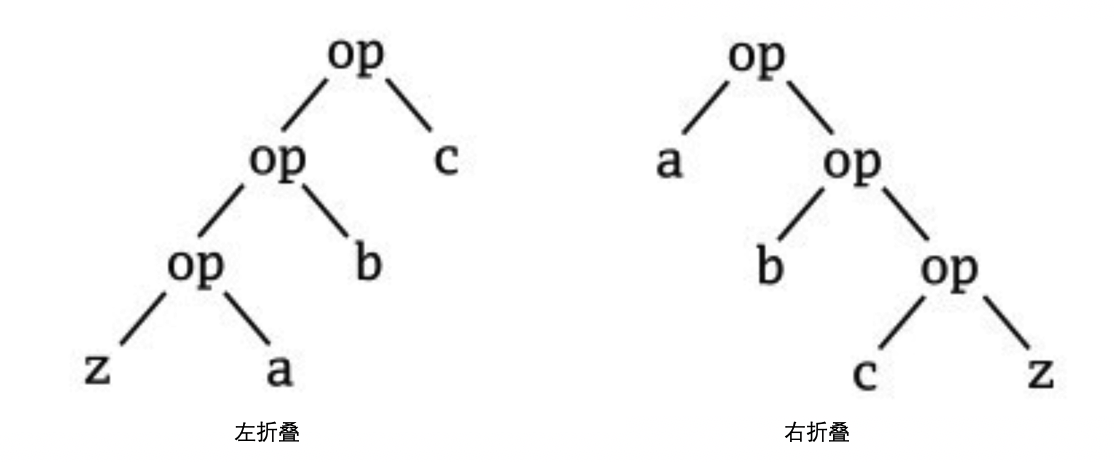
- 左折叠:
(z /: xs)(op)或者xs.foldLeft(z)(op)接收一个列表 xs 和初始化累加器 z,z作为左操作数,从左到右依次对列表中的每个元素调用二元操作 op 来更新 z,返回最终的z(/:操作符形象地表示该操作符会产生一颗向向左靠的操作树)
1 | // foldLeft等价于fold |
- 右折叠:
(xs :\ z)(op)或xs.foldRight(z)(op),接收一个列表 xs 和初始化累加器 z,z作为右操组数,从右到左依次对列表中的每个元素调用二元操作 op 来更新 z,返回最终的z(:\操作符形象地表示该操作符会产生一颗向右靠的操作树)
1 | scala> xs.foldRight("0")(_ + _) |
- scan:与 fold 用法相同,只不过返回的是归约过程中各个累积起的一个列表
xs.scan(z)(op)/xs.scanLeft(z)(op)给定一个初始值和一个归约函数,从左到右返回各个累计值的一个列表xs.scanRight(z)(op)给定一个初始值和一个归约函数,从右到左返回各个累计值的一个列表
1 | scala> abc.scan("0")(_ + _) |
列表检查
- forall:
xs.forall(p)接收一个列表 xs,依次对每个元素应用布尔函数 p,如果所有元素返回值均为true则返回true,否则返回false
1 | scala> List(1,2,3,4).forall(_ < 5) |
- exists:
xs.exists(p)接收一个列表 xs,依次对每个元素应用布尔函数 p,只要有一个元素的返回值为true则返回true,否则返回false
1 | scala> List(1,2,3,4).exists(_ == 4) |
List 伴生对象方法
上面介绍的方法都是List类的方法,还有些方法是定义在全局可访问对象scala.List上的,这是List类的伴生对象,某些操作是用于创建列表的工厂方法,另一些则是对特定形状的列表进行操作。
- 从元素创建列表:List(1,2,3) 这样的字面量只不过是简单地将对象应用到元素1,2,3而已,与List.apply(1,2,3) 是等效的
1 | scala> List(1,2,3) |
- 创建整数区间:
List.range(from, until[, step])创建一个从 from 开始,到until结束(不包含until),步长为step的整数列表
1 | scala> List.range(1,10,2) |
- 创建相同元素的列表:
List.fill(n)(value)创建一个包含 n 个 value 元素的列表
1 | scala> List.fill(10)('1') |
- 创建一个表格化的列表:
List.tabulate(m, n)(f)创建一个 m 行 n 列的二维列表xs,xs(i)(j)=f(i,j), 0 <= i < m, 0 <= j < n
1 | scala> List.tabulate(2,3)(_ * _) |
向量(Vector)
Vector 是一个不可变的索引序列,通过多分支树实现。Vector 是用来解决 List 不能随机存取的一种结构,它在快速随机选择和快速随机更新的性能方面做到很好的平衡,所以目前正被用作不可变索引序列的默认实现方式。当你不知道该选择什么时,Vector是你最好的选择,因为它在Scala集合中是最灵活和高效的。
Vector结构通常被表示成具有多分支的树,每个节点包含最多32个vector元素或者至多32个子树节点,一次间接引用则可以用来表示一个包含至多32*32=1024个元素的vector。从树的根节点经过两跳到达叶节点足够存下有2的15次方个元素的vector结构,经过3跳可以存2的20次方个,4跳2的25次方个,5跳2的30次方个。所以对于一般大小的vector数据结构,一般经过至多5次数组访问就可以访问到指定的元素,这也就是我们之前所提及的随机数据访问时“运行时间的相对高效”。
Vector 创建
1 | // 标准形式 |
Vector 操作
与 List 相比, Vector 的操作没有什么不同,只是效率上有所差异。
1 | scala> vec1 ++ vec3 |
数组缓冲器(ArrayBuffer)
ArrayBuffer 是一个变长数组,目前正被用作可变索引序列的默认实现方式。当新元素总是添加到最后的时候,可以用 ArrayBuffer 来高效地构造一个大型的容器。
ArrayBuffer 创建
在创建 ArrayBuffer 之前必须先引入它:
1 | scala> import scala.collection.mutable |
ArrayBuffer 操作
与 List 相比,ArrayBuffer 支持原地修改操作,ArrayBuffer 的大多数操作,其速度与数组本身无异,因为这些操作直接访问、修改底层数组。
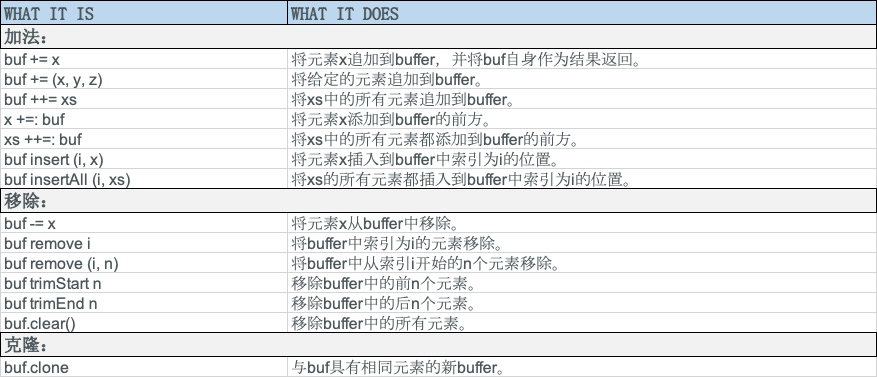
ArrayBuffer 可以通过 += 和 ++= 添加元素或另一个集合中的元素,也可以通过 -= 和 --= 从数组中删除元素或另一个集合中的元素,在删除元素时会从后向前删除,如果找到就删找不到就跳过:
1 | scala> arrb = mutable.ArrayBuffer(1,2,1,2,3) |
ArrayBuffer 还有很多其它方法用来添加或者删除元素:
1 | scala> val a = ArrayBuffer(1, 2, 3) // ArrayBuffer(1, 2, 3) |
ArrayBuffer 还支持原地修改序列中的元素:
1 | // ArrayBuffer 的 updated方法是在原地修改 |
列表缓冲器(ListBuffer)
ListBuffer 是一个可变链表。如果你还需要像使用 List 那样使用可变序列,或者需要将可变序列转化为 List,使用ListBuffer是一个更好的选择。
ListBuffer 创建
在创建 ListBuffer 之前必须先引入它:
1 | scala> import scala.collection.mutable |
ListBuffer 操作
ListBuffer 的操作和 ArrayBuffer类似,通过 toList 方法可以转化为 List:
1 | scala> listb.toList |
数组(Array)
Array 是一个定长数组:Scala 2.8 中数组不再被看作是序列,因为本地数组的类型不是Seq的子类型,而是在数组和 scala.collection.mutable.WrappedArray 这个类的实例之间隐式转换,后者则是Seq的子类
1 | scala> val a1 = Array(1, 2, 3) |
关于Array,需要知道:
- Scala 数组与 Java 数组是一一对应的:Array类型实际上只是数组类型的一个包装器,Scala数组Array[Int]可看作Java的Int[],Array[Double]可看作Java的double[],以及Array[String]可看作Java的String[]
- Scala 数组是一种泛型:可以定义一个Array[T],T可以是一种类型参数或抽象类型
- Scala 数组与 Scala 序列是兼容的:在需要Seq[T]的地方可由Array[T]代替,Scala 数组支持所有的序列操作
不建议经常使用Array类型,除非JVM代码中需要用到。
Array 创建
- 标准做法:作为一个函数来调用Array
1 | scala> val a = Array[Int](5) |
- new 语句:根据给定类型和长度创建数组
1 | scala> val a = new Array[Int](5) |
Array 操作
Array 可原地修改但不能改变其大小:
1 | scala> a |
Array[T] 泛型数组:类型参数 T.ClassTag,当Array[T] 构造时,在任何情况下会发生的是,编译器会寻找类型参数T的一个类声明,这就是说,它会寻找ClassTag[T]一个隐式类型的值。如果如此的一个值被发现,声明会用来构造正确的数组类型;否则,你就会看到一个错误信息
1 | import scala.reflect.ClassTag |
Seq 选择
选择一个 Seq 的时候,你需要考虑两件事:
- 选择线性序列还是索引序列:线性序列方便头尾操作、索引序列方便随机存取;
- 选择可变序列还是不可变序列:可变序列方便原地修改、不可变序列安全无副作用;
主要的不可变序列:
| IndexedSeq | LinearSeq | Description | |
|---|---|---|---|
| List | ✓ | A singly linked list. Suited for recursive algorithms that work by splitting the head from the remainder of the list. | |
| Queue | ✓ | A first-in, first-out data structure. | |
| Range | ✓ | A range of integer values. | |
| Stack | ✓ | A last-in, first-out data structure. | |
| Stream | ✓ | Similar to List, but it’s lazy and persistent. Good for a large or infinite sequence, similar to a Haskell List. | |
| String | ✓ | Can be treated as an immutable, indexed sequence of characters. | |
| Vector | ✓ | The “go to” immutable, indexed sequence. The Scaladoc describes it as, “Implemented as a set of nested arrays that’s efficient at splitting and joining.” |
主要的可变序列:
| IndexedSeq | LinearSeq | Description | |
|---|---|---|---|
| Array | ✓ | Backed by a Java array, its elements are mutable, but it can’t change in size. | |
| ArrayBuffer | ✓ | The “go to” class for a mutable, sequential collection. The amortized cost for appending elements is constant. | |
| ArrayStack | ✓ | A last-in, first-out data structure. Prefer over Stack when performance is important. | |
| DoubleLinkedList | ✓ | Like a singly linked list, but with a prev method as well. The documentation states, “the additional links make element removal very fast.” | |
| LinkedList | ✓ | A mutable, singly linked list. | |
| ListBuffer | ✓ | Like an ArrayBuffer, but backed by a list. The documentation states, “If you plan to convert the buffer to a list, use ListBuffer instead of ArrayBuffer.” Offers constant-time prepend and append; most other operations are linear. | |
| MutableList | ✓ | A mutable, singly linked list with constant-time append. | |
| Queue | ✓ | A first-in, first-out data structure. | |
| Stack | ✓ | A last-in, first-out data structure. (The documentation suggests that an ArrayStack is slightly more efficient.) | |
| StringBuilder | ✓ | Used to build strings, as in a loop. Like the Java StringBuilder. |
序列类型常用操作的性能特点:
| 类型 | 具体类型 | head | tail | apply | update | prepend | append | insert |
|---|---|---|---|---|---|---|---|---|
| immutable | List | C | C | L | L | C | L | - |
| immutable | Stream | C | C | L | L | C | L | - |
| immutable | Vector | eC | eC | eC | eC | eC | eC | - |
| immutable | Stack | C | C | L | L | C | L | L |
| immutable | Queue | aC | aC | L | L | C | C | - |
| immutable | Range | C | C | C | - | - | - | - |
| immutable | String | C | L | C | L | L | L | - |
| mutable | ArrayBuffer | C | L | C | C | L | aC | L |
| mutable | ListBuffer | C | L | L | L | C | C | L |
| mutable | StringBuilder | C | L | C | C | L | aC | L |
| mutable | MutableList | C | L | L | L | C | C | L |
| mutable | Queue | C | L | L | L | C | C | L |
| mutable | ArraySeq | C | L | C | C | - | - | - |
| mutable | Stack | C | L | L | L | C | L | L |
| mutable | ArrayStack | C | L | C | C | aC | L | L |
| mutable | Array | C | L | C | C | - | - | - |
其中,时间复杂度符号解释如下:
| 符号 | 说明 |
|---|---|
| C | 指操作的时间复杂度为常数 |
| eC | 指操作的时间复杂度实际上为常数,但可能依赖于诸如一个向量最大长度或是哈希键的分布情况等一些假设。 |
| aC | 该操作的均摊运行时间为常数。某些调用的可能耗时较长,但多次调用之下,每次调用的平均耗时是常数。 |
| Log | 操作的耗时与容器大小的对数成正比。 |
| L | 操作是线性的,耗时与容器的大小成正比。 |
| - | 操作不被支持。 |
序列操作说明:
| 操作 | 说明 |
|---|---|
| head | 选择序列的第一个元素。 |
| tail | 生成一个包含除第一个元素以外所有其他元素的新的列表。 |
| apply | 索引。 |
| update | 功能性更新不可变序列,同步更新可变序列。 |
| prepend | 添加一个元素到序列头。对于不可变序列,操作会生成个新的序列。对于可变序列,操作会修改原有的序列。 |
| append | 在序列尾部插入一个元素。对于不可变序列,这将产生一个新的序列。对于可变序列,这将修改原有的序列。 |
| insert | 在序列的任意位置上插入一个元素。只有可变序列支持该操作。 |
针对数组/链表,可变/不可变的组合,推荐使用以下四种通用容器类:
| Immutable | Mutable | |
|---|---|---|
| Linear (Linked lists) | List | ListBuffer |
| Indexed | Vector | ArrayBuffer |
总结 Seq 的一般选择原则:
- 如果你需要一个不可变序列,那么首选 List;
- 如果你还需要快速访问不可变序列的中间元素,那么就选 Vector;
- 如果你需要一个可变序列,那么首选 ArrayBuffer;
- 如果你还需要像使用 List 那样使用可变序列,或者需要将可变序列转化为 List,那么就选 ListBuffer;
